
Pour contrer la crise de l'évaluation des IA, Hugging Face rehausse les exigences
François Manens

Ce contenu est réservé aux abonnés La Tribune
Hugging Face a changé sa méthode d'évaluation des IA.
Hugging Face
François Manens
Ce contenu est réservé aux abonnés La Tribune
Hugging Face a changé sa méthode d'évaluation des IA.
Hugging Face
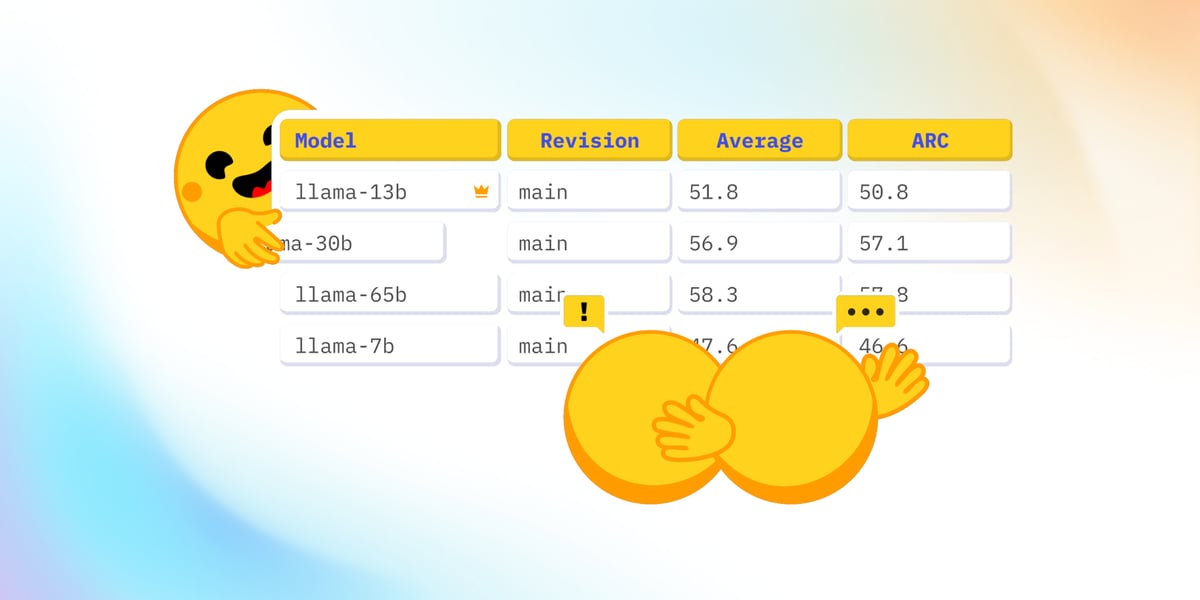
La course aux meilleurs modèles d'intelligence artificielle s'est transformée en une guerre de chiffres. Pour mesurer la performance des IA, les chercheurs leur font passer des tests, aussi appelés benchmarks, avec à la clé des pourcentages de réussite. Ces indicateurs servent ensuite aux ingénieurs à prouver la supériorité de leurs modèles sur ceux de leurs concurrents, dans l'objectif d'attirer utilisateurs et investisseurs. Mais un problème de taille se dessine à court terme : les benchmarks les plus utilisés depuis le début de la vague ChatGPT, fin 2022, commencent à être dépassés par les performances des dernières générations de modèles. Au point qu'une véritable crise de l'évaluation se profile pour le secteur.
Entreprise incontournable de l'écosystème, Hugging Face a décidé de prendre les devants en proposant depuis fin juin de tout nouveaux tests, afin de créer une grille d'évaluation capable d'accueillir les IA de demain. La startup franco-américaine a ainsi mis à jour son classement de performance des modèles open source - les IA dont les développeurs acceptent de partager une partie de leur recette de création - qui pourrait rapidement servir d'inspiration au monde des modèles propriétaires comme ceux de OpenAI, Anthropic, ou Google.
Les benchmarks actuels se confrontent à deux grands difficultés. Pour commencer, les chercheurs pointent leur « saturation » : les modèles d'IA dernier cri tendent de plus en plus vers les 100% de réussite aux tests, avec des scores supérieurs à 80%, voire 90%. Si la trajectoire d'amélioration se poursuit, les modèles de demain devraient réussir à la perfection les évaluations d'aujourd'hui, et les benchmarks ainsi « saturés » ne permettraient plus de les départager. Autrement dit, le secteur à besoin de redimensionner sa grille d'évaluation des modèles avec de nouveaux benchmarks, plus difficiles.
À lire également
Le second problème évoqué par les chercheurs s'appelle la « contamination ». Il concerne d'autant plus les benchmarks les plus anciens, ayant beaucoup circulé en ligne. Concrètement, certaines IA ont appris directement ou indirectement (par le biais de forums de discussion, par exemple), volontairement ou non, les réponses aux questions des tests. En cause, les ingénieurs entraînent leurs IA sur des volumes colossaux de données, dont ils ne communiquent pas le détail, qu'ils ne connaissent d'ailleurs pas le plus souvent.
François Manens
Chez Meta, la responsable de l’IA au travail part en pleine contestation interne
Tibi 3 : les investisseurs institutionnels débloquent 13 milliards d'euros sur 7 ans pour financer la tech
Musique : l'inégale répartition des 319 millions d’euros versés par Spotify aux artistes français
W, le réseau social européen qui compte défier X
