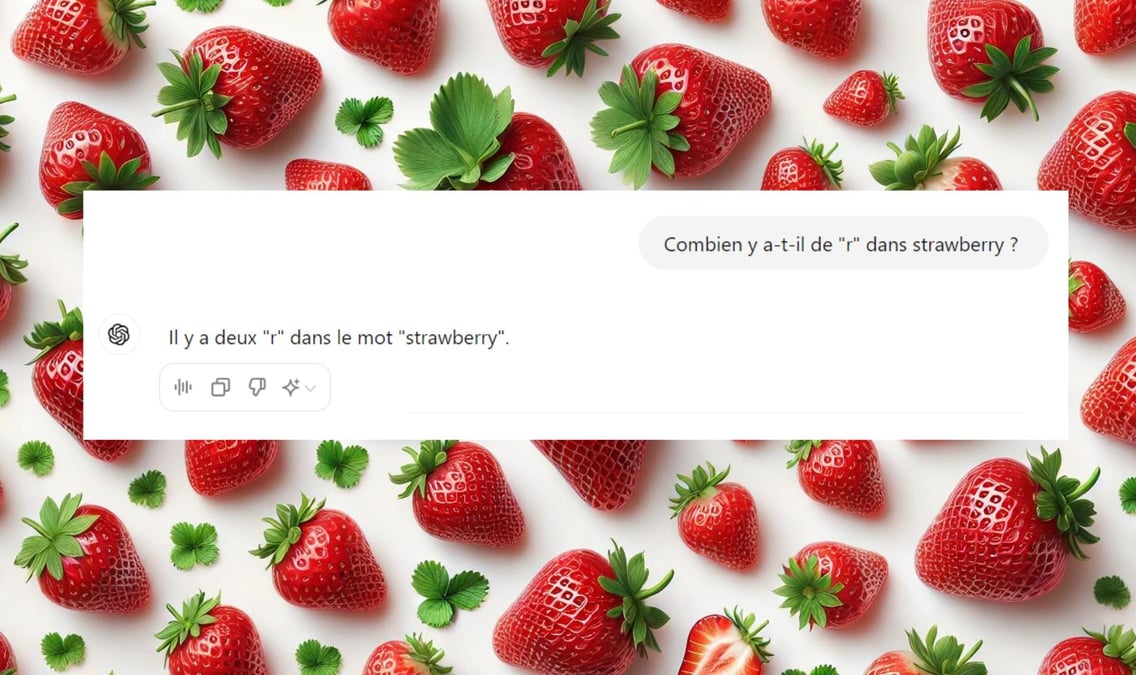
ChatGPT peut faire un résumé décent de Guerre et Paix de Léon Tolstoï ou encore vulgariser les grands principes de la physique quantique, mais aux questions « combien y a-t-il de "r" dans "strawberry" » ? » ou « combien y a-t-il de "n" dans "étonnement" ? », il est probable qu'il se trompe. Ce test est devenu un moyen d'évaluer les intelligences artificielles, plus particulièrement les grands modèles de langage (large language models ou LLM). Régulièrement, des utilisateurs s'amusent à publier des captures d'écran de leur conversation à ce sujet avec le chatbot d'OpenAI, celui de Meta (Meta AI, qui fonctionne grâce à Llama 3.1), ou encore Claude 3 d'Anthropic.
Cette expérience souligne une chose essentielle : « une intelligence artificielle n'a pas un cerveau humain », rappelle Patrick Pérez, PDG de Kyutai, laboratoire français spécialiste de l'IA générative. « Elle peut avoir des capacités presque surhumaines dans certains domaines et ne pas savoir réaliser des tâches qui peuvent paraître parfaitement idiotes, ce qui provoque toujours un effet saisissant. Ces modèles fonctionnent par analogie, ce qui veut dire que s'ils n'ont pas vu ce type de demande suffisamment de fois dans leur entraînement, ils ne sauront pas répondre. »
Pour cette tâche précise (compter le nombre de lettres dans un mot), l'échec du LLM est aussi lié au fonctionnement par tokenisation. Les modèles de langage découpent les textes en petites unités, appelées tokens. Un token peut être une lettre (rarement), un mot, un ensemble de mots... Autrement dit : ChatGPT, ou tout autre grand modèle de langage, ne lit pas. Il ne « voit » pas le texte comme une série de caractères individuels, mais comme une série de concepts encapsulés dans des tokens.