
Accessibilité : comment Google contourne les limites de la reconnaissance vocale
François Manens

Avec le projet Euphonia, Google veut rendre ses systèmes de reconnaissance vocale accessibles au plus grand nombre.
Arnd Wiegmann
François Manens
Avec le projet Euphonia, Google veut rendre ses systèmes de reconnaissance vocale accessibles au plus grand nombre.
Arnd Wiegmann
Demandez "quel temps fait-il ?" à Google Assistant, il vous donnera la météo. Mais cette commande ne fonctionne pas pour tout le monde. Dans certains cas, l'intelligence artificielle de l'assistant ne comprend pas la façon de parler de l'utilisateur. Pour fonctionner correctement, les IA nécessitent de grandes masses de données, mais incorporent les biais de ces données. Dans le domaine de la reconnaissance vocale, les IA sont entraînées à partir d'enregistrements de voix, qui correspondent à une norme, représentative de la majorité. En conséquence, les IA ne sont pas préparées à transcrire les propos de personnes ayant de forts accents ou certaines difficultés d'élocutions (liées, par exemple, à des maladies ou des handicaps). Pour ces personnes, certains outils comme les assistants vocaux (Google Assistant, Alexa, Siri ...) sont donc inutilisables, car ils réalisent trop d'erreurs.
Conscient du problème, Google, comme d'autres entreprises Tech, a lancé plusieurs programmes de recherche dédiés à l'accessibilité de la reconnaissance vocale. L'un d'entre eux, le projet Euphonia, va présenter ses premières recherches à l'occasion de la conférence Interspeech en septembre. Dans un billet de blog, deux chercheurs du projet, Joel Shor et Dotan Emanuel, expliquent les méthodes qu'ils ont utilisées pour permettre à leur système de reconnaissance vocale de faire moins d'erreurs. S'il ne s'agit, d'après les propos des auteurs, que de la "pointe de l'iceberg", ce sont des premières pistes vers des technologies de reconnaissance vocale plus inclusives.
Le principal problème auquel se confrontent les chercheurs de Google est le manque de données. Plus le système de reconnaissance vocale aura d'exemples différents, et donc de récurrences, plus il sera performant. Or, il existe très peu de bases d'enregistrements de personnes avec des élocutions atypiques. D'autre part, même entre personnes confrontées à des troubles de l'élocution similaires, les variations dans la façon de parler peuvent être très importantes. Il devient donc difficile, voire quasi impossible, d'obtenir un important volume de données : les personnes concernées sont relativement peu nombreuses dans chaque cas, et peuvent éprouver de la fatigue à parler pendant de longues durées.
Pour contourner ce manque de données, les chercheurs de Google travaillent en deux temps sur leur système de reconnaissance automatique de la parole ("automated speech recognition" ou ASR, en anglais). D'abord, ils entraînent des réseaux neuronaux, dont la performance a été prouvée, sur des milliers heures d'enregistrement de paroles avec une élocution standard, faciles à trouver, voire à construire. Puis, dans un second temps, ils ajustent leur modèle d'intelligence artificielle avec des enregistrements d'une personne ou d'un sous-groupe à l'élocution atypique.
Dans le cadre du projet Euphonia, Google a choisi de s'intéresser aux personnes atteintes de sclérose latérale amyotrophique (SLA). Cette maladie neurodégénérative affecte le contrôle des muscles, notamment ceux du visage. Un des premiers symptômes peut être la déformation de l'élocution, qui s'aggrave avec l'évolution de la maladie. Grâce à un partenariat avec un institut du MIT spécialisé dans la recherche sur la SLA, Google a pu collecter des données spécifiques à ce groupe. Il a ainsi récupéré 36 heures d'enregistrements, énoncées par 67 personnes atteintes de la maladie. La taille de cet échantillon est rare, car difficile à compiler, mais également bien trop insuffisante pour entraîner une IA performante seule. Cependant, cette base suffit aux chercheurs de Google pour adapter leur système de reconnaissance vocale à des personnes atteintes de SLA, grâce leur méthode en deux temps. Leur IA s'est d'abord entrainée sur une base de milliers d'heures d'enregistrements standards, puis sur la base de 36 heures d'enregistrements de personnes atteintes de SLA.
Chaque jour à 13h, l’essentiel de l’actualité tech.

Les chercheurs ont testé deux architectures de réseaux de neurones différentes pour appliquer leur méthode. Dans les deux cas, ils obtiennent des taux d'erreurs dans la transcription des paroles biens inférieurs avec leur méthode d'ajustement que sans (voir tableau ci-dessous).
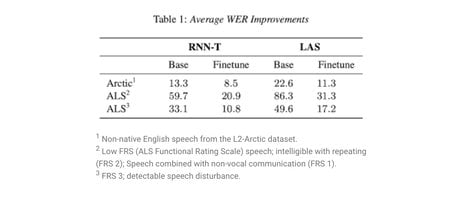
Pour les personnes avec les plus grandes difficultés d'élocution, un des modèles, RNN-T, parvient à n'avoir que 20,9% d'erreurs dans la transcription des mots contre 59,7% sans l'ajustement. Ce taux d'erreur descend à 10,8% pour les personnes dont l'élocution est moins affectée, contre 33,1% sans l'ajustement. Ainsi, leur méthode double presque les performances du système de reconnaissance vocale.
Ces premiers résultats s'avèrent encourageants, et améliorent grandement l'état de l'art. Mais ils ne sont qu'un premier pas, car ils présentent plusieurs limites. D'abord, ces tests ont été effectués sur un vocabulaire simple et limité, et étendre ces résultats à un langage plus général demandera d'autres ressources.
Ensuite, les taux d'erreurs dans la transcription des paroles en texte, supérieurs à 10% voire à 20%, restent trop élevés pour que la technologie soit utilisable de façon fluide. À titre de comparaison, pour l'anglais classique, Google Assistant a aujourd'hui un taux d'erreur dans la retranscription des paroles inférieur à 5%.
Enfin, Google ne teste sa solution que sur le cas de personnes atteintes de SLA, et ne fait que supposer que la méthode sera applicable à d'autres types d'élocutions "non-standards". Mais l'équipe de recherche a tout de même effectué un premier essai hors de ce cas particulier. Ils ont essayé d'ajuster leur modèle de reconnaissance vocale avec des enregistrements de personnes avec de forts accents. La base de données utilisée, baptisée L2 Artic, contient une heure d'enregistrement de 20 personnes différentes, dont l'anglais n'est pas la langue maternelle. Le modèle testé par Google ne réalisait plus que 8,5% d'erreurs dans la retranscription à l'écrit des paroles, contre 13,3% sans l'ajustement.
À lire également
Le projet Euphonia n'en est donc qu'à ses débuts. Les chercheurs vont tester d'autres hypothèses, et cherchent à collecter plus de données pour améliorer leur système. Mais grâce à ce type d'initiative, à terme, les technologies de la maison connectée pourraient ainsi devenir accessibles à toutes et tous.
François Manens








